学习数据结构和算法的框架思维
本文是我对数据结构和算法学习方法的总结,也是本站所有教程的纲领。主要包含两部分:第一,我对数据结构和算法本质的理解;第二,概括几种常用的算法思想。
全文没有复杂的代码,都是我的经验和思考,希望能帮你少走弯路,更透彻地掌握算法。
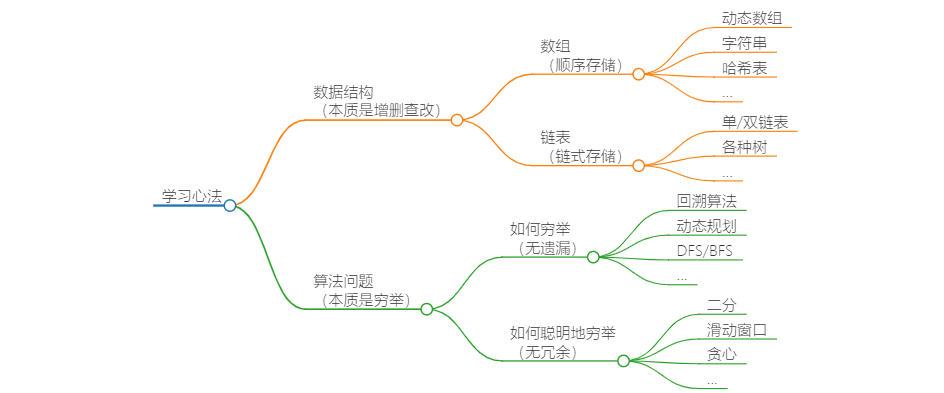
一、总结一切数据结构和算法
各种数据结构的底层存储方式,无非就是数组(顺序存储)和链表(链式存储)两种。
数据结构的关键操作在于遍历和访问,也就是增、删、查、改。
- 种种确定性算法的核心,本质上都是某种形式的枚举(遍历)。 聪明算法和暴力算法的区别在于——能否避免重复或无效的枚举。
枚举的关键在于:不遗漏(把所有可能都考虑到)和不冗余(不重复做无用功)。掌握好算法框架,就能做到不遗漏;充分利用已知信息,就能减少冗余。
如果你能真正理解上面这几句话,那么本文就可以不用看了。如果不理解,那就让我用下面的几千字(以及后面的例题和练习)来慢慢解释。在学习过程中,你可以反复回味这两句话,会大大提高效率。
二、数据结构的存储方式
数据结构的底层存储方式只有两种:数组(顺序存储)和链表(链式存储)。
你可能会问:那哈希表、栈、队列、堆、树、图等等这些数据结构呢?
我们分析问题要像写递归一样,自顶向下,从抽象到具体。上面列出的那些都是“上层建筑”,而数组和链表才是“地基”。因为那些丰富的数据结构,本质上都是在链表或数组之上施加特殊操作、定义不同 API 的结果。
- 队列、栈:既可以用数组实现,也可以用链表实现。用数组实现需要处理扩容和缩容;用链表实现则没有扩容问题,但每个节点需要额外的指针存储空间。
- 图:两种常见存储方式——邻接表(本质是链表)和邻接矩阵(本质是二维数组)。邻接矩阵判断两点是否相连很快,还支持矩阵运算,但稀疏图时浪费空间;邻接表更节省空间,但某些操作效率不如矩阵。
- 哈希表:通过散列函数把键映射到一个大数组里。解决冲突的常见方法中,“拉链法”需要链表来串联冲突元素,操作简单但需要额外指针;“线性探测法”完全依赖数组的连续空间,不需要指针,但操作稍复杂。
- 树结构:用数组实现就是“堆”,因为堆是一棵完全二叉树,用数组存储不需要额外指针,经典应用是二叉堆;用链表实现就是普通的树结构(如二叉搜索树、AVL 树、红黑树等),因为不一定是完全二叉树,所以用数组存储不合适。
总结一下数组和链表的优缺点,记牢这对你以后�选择数据结构很有帮助:
| 存储方式 | 优点 | 缺点 |
|---|---|---|
| 数组 | 连续存储,支持随机访问(通过索引 O(1) 时间找到元素),相对节约空间 | 扩容麻烦(需要重新分配一整块更大的空间并复制所有元素,O(N) 时间);在中间插入/删除需要搬移后续元素(O(N) 时间) |
| 链表 | 没有扩容问题;知道前驱/后继时,插入和删除只需改变指针,O(1) 时间 | 不能随机访问(只能从头遍历);每个元素需要额外空间存储指针 |
三、数据结构的基本操作
任何数据结构的基本操作,本质上就是“遍历 + 访问”,具体就是增、删、查、改。
不同数据结构存在的目的,就是在不同场景下尽可能高效地完成这些操作。这就是数据结构的使命。
如何遍历和访问?从最高层看,无非两种形式:线性和非线性。
- 线性遍历:用
for/while循环(迭代)。 - 非线性遍历:用递归。
下面是最基本的代码框架(以 Java 为例,但思想通用)。
数组遍历(线性)
void traverse(int arr[], int len) {
for (int i = 0; i < len; i++) {
// 访问 arr[i]
}
}
### 链表遍历(兼具迭代和递归)
```java
class ListNode {
int val;
ListNode next;
}
// 迭代方式
void traverse(ListNode head) {
for (ListNode p = head; p != null; p = p.next) {
// 访问 p.val
}
}
// 递归方式
void traverse(ListNode head) {
if (head == null) return;
// 访问 head.val
traverse(head.next);
}
二叉树遍历(非线性递归)
class TreeNode {
int val;
TreeNode left, right;
}
void traverse(TreeNode root) {
if (root == null) return;
traverse(root.left);
traverse(root.right);
}
你看,二叉树的递归遍历和链表的递归遍历是不是很像?二叉树和单链表的结构也类似(一个�节点有两个指针,一个节点有一个指针)。如果再把指针数量增加,就变成 N 叉树:
class TreeNode {
int val;
TreeNode[] children;
}
void traverse(TreeNode root) {
if (root == null) return;
for (TreeNode child : root.children) {
traverse(child);
}
}
N 叉树的遍历再进一步就可以扩展到图的遍历。图可以看作多棵树的组合,只是可能出现环。环的问题很好解决:用一个 visited 布尔数组记录已经访问过的节点即可(具体在图遍历章节会讲)。
所谓“框架”,就是固定的套路。 不管你要做什么增删查改,以上这些遍历结构都是无法脱离的骨架。你可以把这个骨架当作大纲,然后根据具体问题往里添加自己的代码。
四、算法的本质
如果只让我说一句话,我会说:计算机算法(指我们刷题面试中遇到的算法)的本质就是“枚举”。
肯定有人要反驳:难道所有算法问题都是枚举吗?没有例外吗?
例外的确存在,比如某些“一行代码就能解决”的脑筋急转弯题,它们靠的是观察规律,不需要枚举。但这些题数量很少,不必纠结。另外,像密码学算法、机器学习算法,它们的本质是数学原理的编程实现,这类算法不属于我们讨论的“数据结构与算法”范畴。
这里顺便澄清一个常见误解:“算法工程师”做的“算法”和“数据结构与算法”中的“算法”完全是两回事。
- 算法工程师的“算法”更偏向数学建模和调参,计算机只是计算工具。
- 我们学习的“数据结构与算法”更注重计算机思维:如何抽象实际问题、选择合适的数据结构、写出高效的代码。
所以,不要以为学好数据结构与算法就能当算法工程师,也不要以为不当算法工程师就不用学数据结构与算法。坦白说,大部分开发岗位不常直接用到底层算法,但技术岗位的笔试面试几乎都会考察这部分知识,因为它是公认的程序员基本功。
为了区分,我们可以把算法工程师研究的称为“数学算法”,把刷题面试中常用的称为“计算机算法”。本文只关心后者。
计算机的思维其实很简单:计算机最大的特点就是快。你的大脑一秒钟转几圈,CPU 一秒钟能转几亿圈。所以计算机解决问题的方式往往就是——枚举。
举个例子:让你计算一个数组中的最大值,你怎么做?只能用 for 循环遍历每一个元素,找出最大的。没有更好的办法了。这就是枚举,这就是算法。
我刚入门时也有误解,总觉得算法应该像数学公式一样,能“啪”的一下算出答案。比如写一个排列组合算法,别人可能以为我发明了一个公式,能直接输出所有排列。但实际上呢?我只是用回溯算法把整个排列树遍历了一遍,收集所有叶子节点的结果而已。
数学题的思维通常是:找规律、列方程、推导答案。如果你用枚举去做数学题,很可能思路错了。但计算机解决问题的思维恰恰相反:如果你找不到巧妙的数学公式,那就枚举吧!只要复杂度能接受,没有枚举解决不了的问题。
理论上,你不断地随机打乱一个数组,总有一天会得到有序的结果——但这显然不是好算法,因为它可能运行到宇宙末日。
现在技术岗笔试面试考的那些算法题,求最小值、求最优解,本质上就是:把所有可能的解枚举出来,然后找出最值。就这么点事。
五��、枚举的难点
你可能会觉得枚举很容易,但事实上它有两个关键难点:
- 无遗漏:不能漏掉任何一个可能的解,否则答案就错了。
- 无冗余:不能重复计算相同的东西,否则算法会变慢,可能超时。
- 为什么会遗漏? —— 因为你没有掌握正确的枚举框架,不知道怎么把问题转化成代码。
- 为什么会冗余? —— 因为你没有充分利用信息,做了很多重复劳动。
看到一道算法题时,你可以从这两个维度思考:
- 如何枚举? —— 保证不遗漏地找出所有可能解。
- 如何聪明地枚举? —— 尽量避免冗余,用最少的资源找到答案。
5.1 难点一:如何枚举
这类问题通常涉及递归,比如回溯算法和动态规划。
回溯算法:比如排列组合问题。你在草稿纸上可以手动列举:先固定第一位,再固定第二位……但要把这个过程写成代码,需要先把问题抽象成一棵树,然后精确地遍历这棵树的所有节点,不能多也不能少。这正是回溯算法框架要做的事。
动态规划:它比回溯更抽象,因为它不是“遍历”的思维,而是“分解问题”的思维。
什么叫分解问题?举个例子:你面前有一棵树,问树上有多少片叶子?
- 遍历思维:顺着��树枝一片一片去数。
- 分解思维:整棵树的叶子数 = 左子树的叶子数 + 右子树的叶子数。然后左子树的叶子数又可以继续分解,直到空树(0片)或单节点(1片)。
动态规划就是这种“分解问题”的思维。很多同学觉得动态规划难,是因为他们第一步“状态转移方程”(即如何把大问题分解成小问题)就写不出来。我在《动态规划核心框架》中会详细讲解,其实可以用数学归纳法来思考。
5.2 难点二:如何聪明地枚举
这类问题通常使用非递归的技巧,比如二分搜索、滑动窗口、前缀和、贪心算法、并查集等。
- 二分搜索:在有序数组中找一个数,暴力枚举需要 O(N),但二分搜索利用有序性,每次砍掉一半区间,只需要 O(logN)。这就是更聪明的枚举。
- 滑动窗口:求满足条件的子数组,暴力枚举需要 O(N²),滑动窗口用两个指针,一趟扫描即可 O(N)。
- 前缀和 / 差分数组:频繁查询子数组的和或频繁对子数组做增减操作,用前缀和或差分数组可以避免每次循环。
- 贪心算法:它甚至不需要枚举所有解,而是根据某种规律直接选出局部最优,从而得到全局最优。当然,不是所有问题都有这种“贪心性质”。
- 并查集:判断图中两点是否连通,暴力可以用 BFS/DFS,但并查集用数组模拟树,使连通性操作几乎达到 O(1)(实际上是反阿克曼函数,近似常数)。
这些技巧都是大佬们发明的,��你学过就会用,没学过很难自己想出来。所以我们接下来按数据结构分类,帮你梳理这些技巧。
六、数组 / 单链表系列算法
单链表的常用技巧是“双指针”,属于“如何聪明地枚举”。比如判断链表是否有环,暴力做法是用哈希表记录走过的节点,但快慢指针可以做到 O(1) 空间。
数组的常用技巧也是双指针,但形式更丰富,包括左右指针、快慢指针等。
- 二分搜索:可以看作左右指针从两端向中间靠拢。模板在《二分搜索框架详解》中给出。
- 滑动窗口:典型的快慢指针,用于子数组 / 子字符串问题。模板在《滑动窗口算法框架详解》中。
- 前缀和:预计算
preSum数组,快速求任意子数组的和。 - 差分数组:维护
diff数组,快速对子数组做统一的增减操作。
这些技巧比较固定,只要见过了,用起来不会太难。接下来稍微难一点的是二叉树。
七、二叉树系列算法
二叉树非常重要,因为它是几乎所有高级算法(递归、回溯、动规、BFS)的基础。如果你觉得递归难,那就多刷二叉树题。
二叉树题目的递归解法通常有两种思路:
- 遍历一遍二叉树得出答案(对应回溯算法思想)
- 通过分解问题计算出答案(对应动态规划思想)
7.1 遍历的思维模式
比如计算二叉树的最大深度,你可以这样写(遍历一遍树,记录最大深度):
class Solution {
int res = 0; // 记录最大深度
int depth = 0; // 记录当前深度
int maxDepth(TreeNode root) {
traverse(root);
return res;
}
void traverse(TreeNode root) {
if (root == null) {
res = Math.max(res, depth);
return;
}
depth++; // 进入节点,深度加一
traverse(root.left);
traverse(root.right);
depth--; // 离开节点,深度减一
}
}
这段代码和回溯算法的模板非常相似(进入递归前做选择,离开后撤销选择)。所以,回溯算法的本质就是遍历多叉树。
7.2 分解问题的思维模式
同样的“计算最大深度”,你也可以用分解问题的方式写:
int maxDepth(TreeNode root) {
if (root == null) return 0;
int leftMax = maxDepth(root.left);
int rightMax = maxDepth(root.right);
return Math.max(leftMax, rightMax) + 1;
}
这个写法更简洁,和动态规划的递归解法(�比如凑零钱问题)结构一致。动态规划的本质就是把大问题分解成子问题,再组合答案。
7.3 两种思路的对比
再看二叉树的前序遍历。通常我们用遍历思维:
List<Integer> res = new LinkedList<>();
void traverse(TreeNode root) {
if (root == null) return;
res.add(root.val); // 前序位置
traverse(root.left);
traverse(root.right);
}
但你也可以用分解思维:前序遍历结果 = 根节点 + 左子树的前序遍历 + 右子树的前序遍历。
List<Integer> preorder(TreeNode root) {
List<Integer> res = new LinkedList<>();
if (root == null) return res;
res.add(root.val);
res.addAll(preorder(root.left));
res.addAll(preorder(root.right));
return res;
}
中序、后序遍历同理。
7.4 层序遍历(BFS)
除了 DFS(深度优先,即回溯/动归),另一个重要算法是 BFS(广度优先)。BFS 的模板来自二叉树的层序遍历:
void levelTraverse(TreeNode root) {
if (root == null) return;
Queue<TreeNode> q = new LinkedList<>();
q.offer(root);
int depth = 1;
while (!q.isEmpty()) {
int sz = q.size();
for (int i = 0; i < sz; i++) {
TreeNode cur = q.poll();
// 访问 cur
if (cur.left != null) q.offer(cur.left);
if (cur.right != null) q.offer(cur.right);
}
depth++;
}
}
图论中的很多算法(如 Dijkstra 最短路、拓扑排序、二分图判定)都是在这个 BFS 模板上扩展出来的。
八、最后总结
我们常说:“刷题是必须的,但聪明的刷题应该做到刷一道题能顶十道题,否则题库永远刷不完。”
怎么做到呢?要有框架思维——提炼本质,寻找那些不变的结构。一个算法技巧可以包装出成千上万道题,如果你能一眼看穿它们的本质,那么一万道题就等于一道题,何必浪费时间?
这就是框架的力量。它能让你在快睡着的时候,依然写出正确的程序;就算你暂时忘了某个具体算法的细节,只要你掌握这种思维方式,也能比大多数人高一个维度。
授人以鱼不如授人以渔。算法真的没那么难,只要有心,谁都可以学好。希望你能培养出成体系的思维方法,享受支配算法的乐趣,而不是被算法支配。